Zacznij ogarniać ML.
Odkryj Data Science.
Zrozumiesz fundamenty data science, nauczysz się przygotowywać dane i zrobisz pierwszy projekt machine learningowy w Pythonie. Bez chaosu, od podstaw, krok po kroku.
-
Poznasz Pandas, EDA i najważniejsze etapy przygotowania danych do modelu.
-
Zrozumiesz różnicę między regresją, klasyfikacją, klasteryzacją i innymi podejściami ML.
-
Przejdziesz przez pierwszy projekt w scikit-learn i zobaczysz, jak wykorzystać AI w pracy z danymi.

Zaczniesz korzystać z ML jak profesjonalista
-
Solidne fundamenty – zrozumiesz, czym właściwie jest data science i jak różni się od analizy danych, data engineeringu czy AI.
-
EDA bez chaosu – poznasz statystyki opisowe, wartości odstające i korelacje między zmiennymi, czyli rzeczy potrzebne zanim odpalisz model.
-
Przygotowanie danych do modelu – przejdziesz przez braki danych, kodowanie zmiennych kategorycznych, podział na train i test oraz skalowanie cech.
-
Najważniejsze pojęcia ML – ogarniesz regresję, klasyfikację, klasteryzację oraz różnicę między uczeniem nadzorowanym i nienadzorowanym.
Wejdziesz do świata Data Science z praktycznymi umiejętnościami
-
Praktyka w scikit-learn – zobaczysz, jak wygląda praca z biblioteką używaną do budowania pierwszych modeli machine learningowych.
-
Pierwszy projekt ML – przejdziesz krok po kroku przez przykład regresji, dzięki czemu teoria zacznie mieć sens.
-
AI w data science – poznasz praktyczny przykład użycia API OpenAI i zobaczysz, jak nowoczesne narzędzia mogą wspierać pracę z danymi.
-
Certyfikat ukończenia – po kursie otrzymasz imienny dokument, który możesz dodać do LinkedIna i portfolio.
Teraz tylko
Dostępne też w KajoDataSpace
Program kursu
Sprawdź, co przerobisz krok po kroku w kursie Wstęp do Data Science w Pythonie.
Moduł 1
Fundamenty Data Science i przygotowanie środowiska
- Wstęp do kursu — poznasz założenia kursu i zobaczysz, jak traktować Data Science jako rozwinięcie kompetencji analitycznych.
- Czym właściwie jest Data Science — zrozumiesz, czym jest Data Science oraz jak łączy statystykę, programowanie i wiedzę domenową.
- Ekosystem Pythona — Pandas, NumPy, scikit-learn — poznasz najważniejsze biblioteki używane w Data Science i zobaczysz, do czego służą w praktyce.
- Setup praca w Google Colab cz. 1 — przygotujesz środowisko pracy w Google Colab i zrobisz techniczny start do pracy w notebookach.
- Setup praca w Google Colab cz. 2 — przejdziesz przez tworzenie notebooka, komórki kodu i tekstu, Markdown, ładowanie pliku CSV, pracę z Pandas oraz użycie wbudowanego agenta AI.
Moduł 2
Eksploracyjna analiza danych
- Statystyki opisowe cz. 1 — załadujesz dataset diamentów, sprawdzisz kolumny, typy danych, braki, duplikaty i pierwsze statystyki.
- Statystyki opisowe cz. 2 — rozwiniesz interpretację rozkładów, miar centralnych, zmienności i wizualizacji danych.
- Wykrywanie wartości odstających cz. 1 — poznasz outliery, metodę IQR, boxploty oraz strategie: usuń, zostaw, przekształć albo wydziel.
- Wykrywanie wartości odstających cz. 2 — pogłębisz praktyczne decyzje dotyczące wartości odstających i ich wpływu na późniejsze modelowanie.
- Korelacje między zmiennymi cz. 1 — poznasz korelację Pearsona i Spearmana, zbudujesz macierz korelacji, heatmapę i zobaczysz problem multikolinearności.
- Korelacje między zmiennymi cz. 2 — rozwiniesz interpretację relacji w danych oraz zależności między cechami numerycznymi i kategorycznymi.
Moduł 3
Przygotowanie danych do modelu
- Przygotowanie danych do modelu — poznasz pełny pipeline przygotowania danych: czyszczenie, encoding, podział, skalowanie i modelowanie.
- Obsługa brakujących danych cz. 1 — nauczysz się wykrywać, wizualizować i rozumieć braki danych oraz poznasz MCAR, MAR, MNAR, dropna, fillna, imputację i flagi braków.
- Obsługa brakujących danych cz. 2 — pogłębisz wybór strategii obsługi braków w zależności od ich przyczyny i wpływu na model.
- Kodowanie danych kategorycznych cz. 1 — zrozumiesz, dlaczego modele ML potrzebują liczb i poznasz Label Encoding, One-Hot Encoding, Ordinal Encoding oraz Target Encoding.
- Kodowanie danych kategorycznych cz. 2 — rozwiniesz praktyczne zastosowanie encoderów i dobór metody do konkretnego typu danych.
- Podział zbioru danych na zbiór treningowy i testowy cz. 1 — poznasz train_test_split, X i y, test_size, random_state oraz stratify.
- Podział zbioru danych na zbiór treningowy i testowy cz. 2 — rozwiniesz praktyczne aspekty proporcji podziału, walidacji i ryzyka wielokrotnego podglądania zbioru testowego.
- Skalowanie cech (Feature Scaling) cz. 1 — poznasz StandardScaler, MinMaxScaler i RobustScaler oraz zasadę wykonywania fit tylko na zbiorze treningowym.
- Skalowanie cech (Feature Scaling) cz. 2 — pogłębisz temat wyboru skalera, wpływu outlierów i poprawnej kolejności operacji w pipeline.
Moduł 4
Podstawy machine learningu
- Na czym polega uczenie nadzorowane i nienadzorowane — poznasz supervised learning i unsupervised learning oraz różnice między regresją, klasyfikacją, klasteryzacją i wykrywaniem anomalii.
- Regresja liniowa cz. 1 — wytrenujesz Linear Regression na danych o diamentach i poznasz metryki MAE, RMSE oraz R².
- Regresja liniowa cz. 2 — rozwiniesz interpretację wyników, współczynników modelu i jakości predykcji.
- Klasyfikacja cz. 1 — poznasz regresję logistyczną, próg decyzyjny, confusion matrix, accuracy, precision, recall i F1 score.
- Klasyfikacja cz. 2 — pogłębisz praktykę trenowania i oceny modeli klasyfikacyjnych oraz interpretowania wyników.
- Klasteryzacja (clustering) cz. 1 — poznasz K-Means, klastrowanie hierarchiczne, dendrogram, metodę łokcia, centroidy i interpretację klastrów.
- Klasteryzacja (clustering) cz. 2 — rozwiniesz praktyczną interpretację segmentów i wizualizację wyników grupowania.
- Inne modele ML — zobaczysz wprowadzający przegląd XGBoost, Deep Learning, NLP i Reinforcement Learning.
Moduł 5
scikit-learn, kompletny projekt ML i AI w Data Science
- Wstęp do scikit-learn cz. 1 — poznasz Estimator API, estymatory, parametry, atrybuty, transformery, predyktory oraz metody fit, transform, predict i score.
- Wstęp do scikit-learn cz. 2 — rozwiniesz pracę z dokumentacją, parametrami modeli i schematem korzystania z różnych estymatorów.
- Pierwszy projekt uczenia maszynowego cz. 1 — przejdziesz przez kompletny projekt regresyjny na danych o używanych samochodach: EDA, czyszczenie, feature engineering, encoding, train/test split, scaling i trenowanie modeli.
- Pierwszy projekt uczenia maszynowego cz. 2 — rozwiniesz porównanie modeli, interpretację wyników i możliwe kierunki poprawy modelu.
- AI w Data Science (API OpenAI) cz. 1 — skonfigurujesz API OpenAI i wykorzystasz AI do interpretacji danych, statystyk, korelacji, feature engineeringu i wyników modeli.
- AI w Data Science (API OpenAI) cz. 2 — rozwiniesz praktyczne użycie AI jako wsparcia w analizie, komentowaniu wyników i pracy w notebooku.

Zobacz lekcje przykładowe
Kurs, który stale rozwijam
Mój kurs to coś więcej niż tylko nagrane lekcje. Regularnie dodaję nowe zestawy danych, które możesz wykorzystać do ćwiczeń i rozwijania swoich umiejętności.
Każdy dataset jest ręcznie wybrany i opracowany przeze mnie, wraz z komentarzem, jak można go analizować. Dzięki temu kurs pozostaje aktualny, praktyczny i dostosowany do realnych wyzwań analizy danych.
W świecie analizy danych zawsze pojawiają się lepsze sposoby na rozwiązywanie problemów – dlatego ten kurs nie stoi w miejscu! Regularnie dodaję nowe techniki, tipy i praktyczne porady, które pomagają Ci szybciej i efektywniej pracować.
Każda nowa wskazówka jest ręcznie opracowana i bazuje na realnych wyzwaniach, z którymi możesz się spotkać. Dzięki temu kurs stale się rozwija i dostarcza Ci wartościową wiedzę w praktycznej formie.
Kurs stale się rozwija, a ja regularnie dodaję nowe techniki oraz zestawy danych. Jeśli masz propozycję, co warto omówić – napisz!
Analizuję propozycje kursantów i wybieram najciekawsze tematy, które pomagają w nauce i rozwijaniu umiejętności analitycznych.
Teraz tylko
Dostępne też w KajoDataSpace
Możesz sprawdzić ten kurs
bez ryzyka.
Stworzyłem kurs tak, byś mógł / mogła zacząć bez względu na swoje obecne umiejętności i jednocześnie zyskać mnóstwo wartości, wiedzy i umiejętności. Jeśli mimo wszystko zawiodę Twoje oczekiwania, oddam Ci pieniądze.
Abym mógł to zrobić, po prostu napisz do mnie e-maila w ciągu 14 dni od pierwszej transakcji na kajo@kajodata.com.
Tu nie ma żadnego ryzyka.
Jest tylko szansa, którą możesz wykorzystać.
Najczęstsze pytania
Czy to jest jednorazowa płatność?
Tak. Płacisz raz i dostajesz dostęp na rok. To nie jest subskrypcja, więc płatność nie odnawia się automatycznie.
Czy kurs kończy się certyfikatem?
Tak, kurs kończy się certyfikatem, dostępnym w polskiej i angielskiej wersji językowej. Jest to ważne potrwierdzenie Twooich osiągnięć. Każdy certyfikat jest unikatowym z unikalnym kluczem do weryfikacji online w ramach aplikacji Certesto.
Czy wystawiasz fakturę?
Jasne! Prowadzę legalną działalność gospodarczą w Polsce (NIP: 675-176-58-70). Oczywiście obsługuję KSeF 🙂
Jakiego oprogramowania potrzebuję?
Żadnego 😀 Korzystamy z Google Colab, który zapewnia środowisko do nauki i eksperymentowania z danymi w Pythonie.
Dlaczego Katarzyna Zielina jest autorką kursu?
Ponieważ Kajo nie jest alfą i omegą 😉 Zawsze zależy mi na wysokim poziomie merytorycznym, a to oznacza, że w przypadku niektórych technologii / umiejętności lepiej jest skorzystać z wiedzy eksperta. Katarzyna Zielina jest takim ekspertem, a jej umiejętności zostało potwierdzone wcześniej także na webinarach na KajoDataSpace. Każda lekcja została również przeze mnie osobiście sprawdzona.
Czy kurs jest od podstaw?
Nie, ten kurs zakłada podstawową wiedzę z Pythona. Jeżeli takiej wiedzy nie masz, skorzystaj z mojego kursu Analiza Danych w języku Python.
Czy w kursie jest kontakt z prowadzącym?
Nie. Ten kurs daje dostęp materiałów kursowych, bazy wiedzy oraz dodatkowych zestawów danych, ale nie zawiera kontaktu z prowadzącym ani społeczności. Jeśli zależy Ci na społeczności, webinarach i kontakcie, sprawdź KajoDataSpace.
Czy mogę zwrócić kurs, jeśli to nie dla mnie?
Tak. Masz 14 dni na sprawdzenie kursu. Jeśli uznasz, że to nie jest dla Ciebie, możesz napisać w sprawie zwrotu na kajo@kajodata.com.
Mam inne pytanie...
Napisz do mnie na maila: kajo@kajodata.com
Teraz tylko
Dostępne też w KajoDataSpace
Co mówią osoby, które uczą się z KajoData?
Opinie pochodzą z kursów, wiadomości od kursantów i społeczności KajoDataSpace. Różne historie, różne punkty startu, ale bardzo podobny cel: ruszyć z miejsca i zacząć lepiej pracować z danymi.

KajoData pomógł mi dostać pracę, którą zawsze chciałem wykonywać. Wiedza i pasja jaką widać w jego filmach ogromnie motywuje do działania!

Lekcje z Kajem pomogły mi urealnić proces przebranżowienia. Jeśli chcecie zmienić pracę, a nie wiecie od czego zacząć, to warto odezwać się do Kaja.

Szczerze polecam! Jeżeli ktoś szuka prostego i zrozumiałego materiału, to moim zdaniem ten kurs będzie strzałem w dziesiątkę.
Historie ze społeczności KajoDataSpace
Kilka wiadomości od osób, które uczyły się analizy danych, budowały projekty, przygotowywały się do rekrutacji albo realnie zmieniały swoją ścieżkę zawodową.
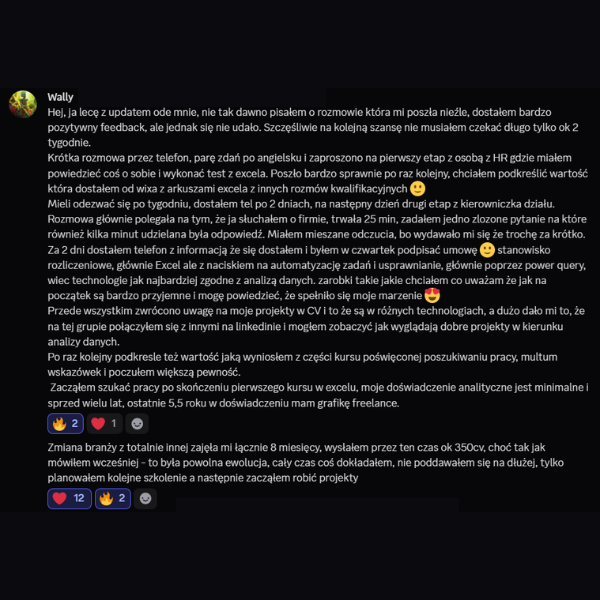
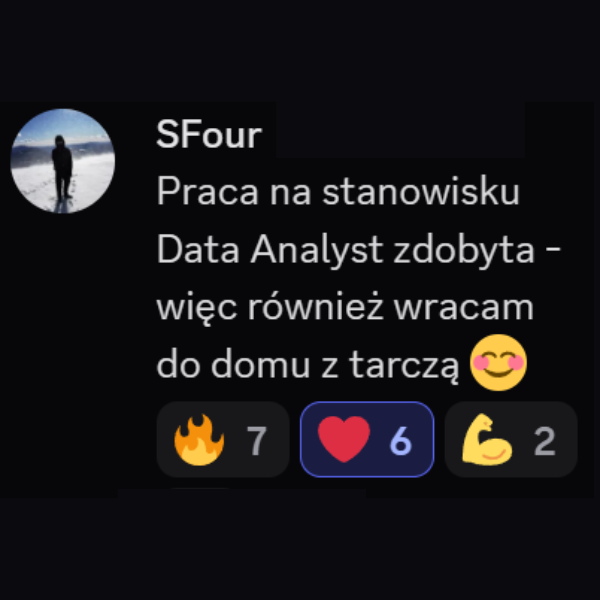
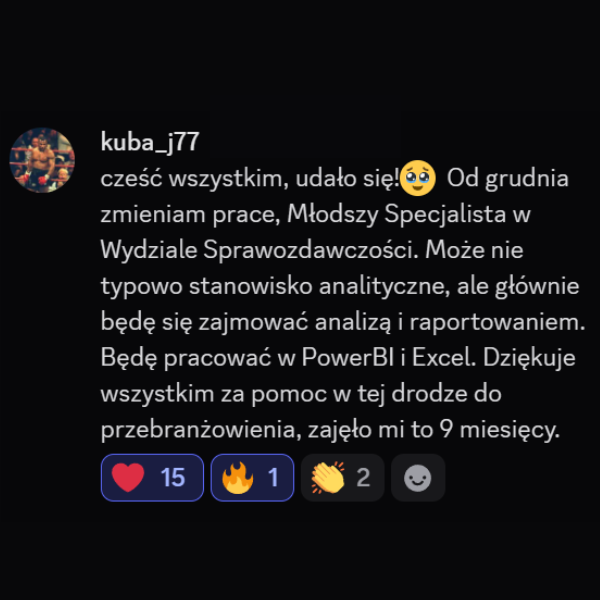
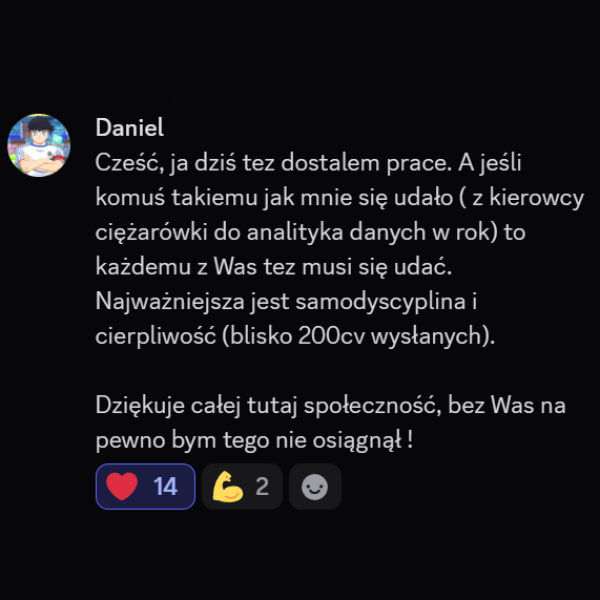
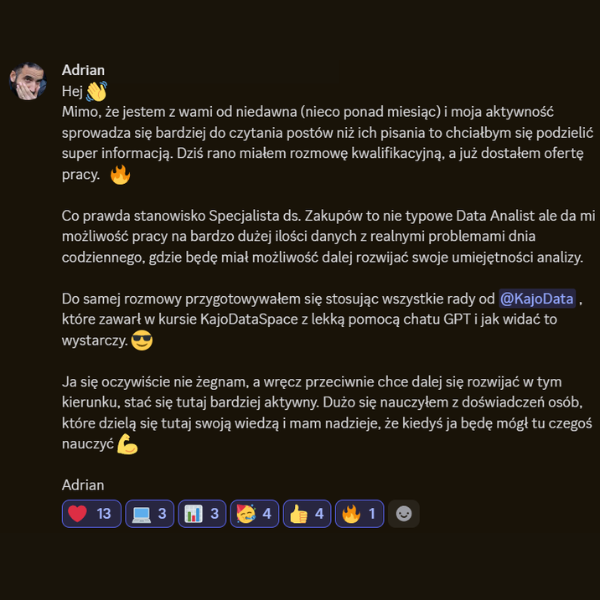
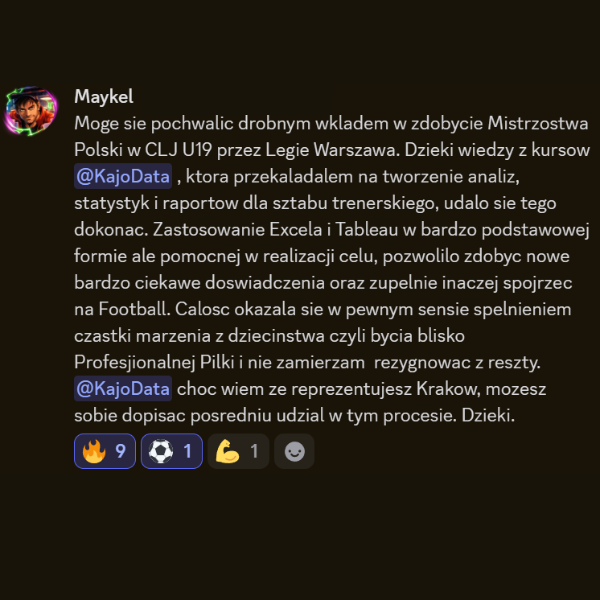
Teraz tylko
Dostępne też w KajoDataSpace